
La detección masiva es una parte esencial de la lucha contra la propagación del coronavirus. Sin embargo, ¿cómo afrontar una posible escasez de reactivos y materiales? La respuesta está en la aplicación de pruebas en una mezcla de muestras y en el uso de matemáticas.
Con el temor de una segunda ola de COVID-19, muchos expertos coinciden en que se necesita un plan de detección a gran escala para detener la propagación del coronavirus. Las pruebas inmunológicas, serológicas o pruebas de antígenos realizadas en muestras representativas de la población, también permitirían estimar la prevalencia de la enfermedad, determinar el grado de inmunidad colectiva y adaptar las medidas de la gestión de la pandemia.
Para que la implementación de una estrategia de detección masiva tenga éxito, se tiene que contar con los recursos humanos y materiales adecuados. Con la creciente demanda en todo el mundo, la escasez de reactivos necesarios para los análisis de laboratorio se vislumbra en el horizonte; siendo ya una preocupación para las autoridades de salud pública de Canadá y en el resto del mundo.
Asumiendo que la mayoría de las pruebas son (afortunadamente) negativas, ¿pueden las matemáticas proporcionar una mejor estrategia de detección? En efecto, aplicando pruebas a mezclas de muestras cuidadosamente construidas.
La prueba grupal
Imaginemos que un laboratorio recibió 100 muestras con el objetivo de hacer un análisis. Las divide al azar en $5$ grupos de $20$. En cada grupo se utiliza la mitad de cada una de las $20$ muestras para crear una mezcla en la cual se aplicará la prueba de detección.
Si la prueba realizada a partir de dicha mezcla es negativa, se puede concluir de inmediato que ningún miembro del grupo está infectado. Si la prueba es positiva, se realizan pruebas individuales a la segunda mitad de cada una de las $20$ muestras.
Si las $100$ pruebas originales provienen de personas sanas, el procedimiento puede comprobarlo con 5 pruebas en lugar de $100$. Si una sola persona está infectada, sólo se necesitan $5 + 20 = 25$ pruebas para identificarla. Si dos personas están infectadas, también se pueden identificar con $25$ pruebas si están en el mismo grupo, pero con $5 + 20 + 20 = 45$ pruebas si pertenecen a grupos diferentes. Se procede de la misma manera si hay tres o más personas infectadas.
Como podemos ver, la detección grupal permite un ahorro significativo. Por supuesto, siempre que la sensibilidad y la especificidad de la prueba no se vean afectadas por la mezcla de muestras. Tal y como lo asumimos aquí y como a menudo pasa en la práctica.
El laboratorio también habría podido aplicar la misma estrategia de detección a $10$ grupos de $10$ muestras. Si una sola persona estuviera infectada, solamente se habrían necesitado $20$ pruebas para identificarla. Sin embargo, serían necesarias $10$ pruebas para concluir que nadie estuviera infectado.
¿Cuál de estas dos estrategias es mejor? ¿Y existe una alternativa más eficaz? La respuesta depende de la prevalencia de la enfermedad, es decir, de la proporción de la población que está infectada.
En una nota publicada en 1943 en The Annals of Mathematical Statistics, el estadounidense Robert Dorfman informa que, en su forma más básica, la detección grupal ya se había utilizado durante la Segunda Guerra Mundial para detectar casos de sífilis entre los conscriptos. Hoy la estrategia se ha estandarizado. En actualidad, múltiples variantes se utilizan en toda América del Norte para detectar la presencia de VIH, la influenza o el virus del Nilo Occidental.
Optimizar el algoritmo
Dorfman mostró cómo determinar el tamaño óptimo del grupo basándose en la prevalencia $p \in [0, 1]$ de la enfermedad. Llamemos el tamaño del grupo $n ≥ 2$ y supongamos que sus miembros constituyen una muestra aleatoria representativa de la población.
Si $X$ denota el número desconocido de personas infectadas en el grupo, podemos suponer que esta variable sigue una distribución binominal 1 con parámetros $n$ y $p$, y por lo tanto
\[\text{Pr}(X=0)=(1–p)^n,\]
como cada individuo tiene una probabilidad $1 – p$, de estar sano, y
\[\text{Pr}(X>0)=1–\text{Pr}(X=0)=1–(1–p)^n.\]
Si $X = 0$, sólo haremos $N = 1$ prueba. Sin embargo, si $X >0$, haremos $N = n+1$ pruebas. En promedio, el número de pruebas que realizaremos, el concepto llamado la esperanza de $N$ y denotado por $E(N)$, es igual a
\[\begin{array}{r c l}E(N) &=&1×\text{Pr}(X=0)+(n+1)×\text{Pr}(X>0) \\&=& n+1–n(1–p)^n.\end{array}\]
Ésta es una función creciente en $p.$ Si $p = 0$, tenemos $E(N) = 1$, lo cual es obvio, ya que nadie tiene la enfermedad y por lo tanto una sola prueba es suficiente para confirmarlo. Si $p = 1$, tenemos $E(N) = n+1$, por lo que la primera prueba será necesariamente positiva.
Para cada valor de $p \in [0, 1]$, es posible determinar el costo relativo vinculado al uso de la detección grupal mediante el estudio del comportamiento del radio
\[E(N)/n=1+1/n–(1–p)^n\]
en función de la variable $n$. Cuanto menor sea $E(N)/n$, más eficaz es utilizar pruebas grupales, siempre que, por supuesto, la proporción sea menor de 1. Cuando $p = 0$, tenemos $E(N)/n = 1/n$, de modo que lo mejor es tomar n tan grande como sea posible. Cuando $p = 1$, siempre se cumple
\[E(N)/n=1+1/n>1\]
como la prueba grupal siempre es positiva y por lo tanto, deja de ser útil.

Figura 1
Gráfica de la curva $100 \times E(N)/n$ en función de $n$ para diferentes valores de $p$: 1% (negro), 2% (marrón), 5% (naranja), 8% (rojo), 10% (azul) y 15% (verde).
Para un valor fijo de $p$, la función $100 \times E(N)/n$ representa el porcentaje promedio de pruebas realizadas según el tamaño del grupo $n$. La figura muestra el gráfico de esta función para diferentes valores de $p$, correspondientes a una prevalencia del 1% (negro), 2% (marrón), 5% (naranja), 8% (rojo), 10% (azul) y 15% (verde). Como puede observarse, el tamaño óptimo de las mezclas, el cual corresponde al mínimo de la curva, varía según la proporción, $p$, de individuos infectados en la población. En la siguiente tabla, realizada por Dorfman, se muestra el tamaño óptimo de $n$ para algunos valores de $p$.
| $p$ (%) | $n$ | El costo relativo (%) |
| 1 | 11 | 20 |
| 2 | 8 | 27 |
| 5 | 5 | 43 |
| 8 | 4 | 53 |
| 10 | 4 | 59 |
| 15 | 3 | 72 |
Generalización
El protocolo de la prueba descrito anteriormente es un ejemplo de un algoritmo adaptativo de dos etapas. Decimos que es adaptativo porque la elección (y por lo tanto el número) de pruebas que realizamos en la segunda etapa depende del resultado de la prueba realizada en la primera etapa. Hay varias maneras de mejorar el rendimiento de este tipo de algoritmo. En particular, el procedimiento se puede ampliar si aumentamos el número de etapas.
A continuación presentamos un algoritmo clásico, llamado algoritmo de división binaria, el cual tiene ciertas propiedades de optimalidad (ver figura 2).
a) Tomamos un número entero $n$ de la forma $n = 2^s$ y realizamos k etapas de pruebas, donde $k ≤ s+1$.
b) En la primera etapa, se aplica una prueba de detección a una mezcla de muestras de todo el grupo.
c) Si la evaluación es positiva, el grupo se divide en dos subgrupos de $2^{s-1}$ muestras y se aplica una prueba a una mezcla de cada uno de los subgrupos.
d) Continuamos de esta manera hasta la etapa $k$, donde hacemos pruebas individualmente a los miembros de un subgrupo declarado positivo en la etapa anterior. En el caso particular, $k = s+1$, este subgrupo tendrá sólo dos miembros restantes.

Figura 2
Representación gráfica de un algoritmo adaptativo de división binaria de $5$ rondas aplicado a una muestra inicial de $n = 2^4 = 16$ individuos, de los cuales sólo uno está infectado.
Si el grupo tiene un solo individuo infectado, este algoritmo lo identificará exactamente en $s+1 = \log_2(n) + 1$ etapas. Como regla general, cuanto mayor sea el número de etapas, mejores serán los ahorros resultantes de esta estrategia. Pero si se necesitan de 24 a 48 horas para que una prueba sea concluyente, el tiempo de entrega de los resultados puede ser contraproducente. Hay que tener en cuenta que esta mejora en la estrategia requiere un gran número de muestras biológicas. Este hecho no se considera un problema y así lo asumiremos en todos los algoritmos presentados a continuación.
Un algoritmo no adaptativo
Para controlar mejor el tiempo de entrega de resultados, también se puede considerar el uso de métodos no adaptativos de la prueba de detección grupal. Estos protocolos consisten en realizar una sola etapa, lo que permite hacer todas las pruebas simultáneamente. Este tipo de estrategias es muy eficaz para detectar casos cuando se dispone de una estimación fiable de la prevalencia de la enfermedad.
Expliquemos este concepto usando el siguiente ejemplo, desarrollado por un equipo ruandés de investigadores como parte de la lucha actual contra el COVID-19. Primero formamos una muestra aleatoria de tamaño $n = 3^m$. Luego establecemos una correspondencia entre los $3^m$ individuos y los puntos de un hipercubo discreto $\{0, 1, 2\}^m$. Consulte la figura 3 para ver la ilustración en el caso de $m = 3$.
La metodología propuesta consiste en realizar simultáneamente $3m$ pruebas a mezclas de muestras, cada una de las cuales contiene $3^{3m-1}$ individuos. Sin embargo, las mezclas se preparan de una forma muy particular, usando secciones transversales del hipercubo. En efecto, $x_1, \ldots, x_m$ denotan los ejes de coordenadas del hipercubo, cada una de las combinaciones corresponde entonces a los individuos ubicados en el hiperplano $x_i = t$, donde $i \in \{1, \ldots, m\}$ y $t \in \{0, 1, 2\}$ es una sección transversal de $3^{m-1}$ individuos.
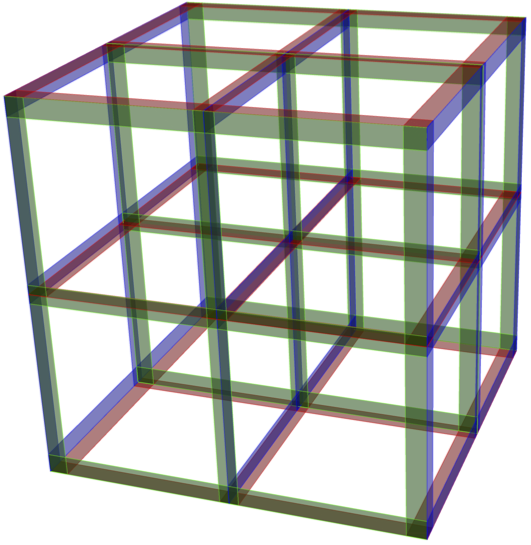
Figura 3
Hipercubo discreto. Cada punto de la red corresponde a un individuo en una muestra aleatoria de tamaño $n = 3^3 = 27$. Los individuos de $3^2 = 9$ que forman cada una de las $9$ mezclas están ubicados a lo largo de una sección transversal roja, azul o verde.
Cuando $m = 3$, como en la figura 3, realizamos $3 \times 3 = 9$ pruebas en grupos de $3^2 = 9$ individuos. Cuando $m = 4$, que es el valor utilizado para la implementación en Ruanda, realizamos $12$ pruebas a partir de una muestra aleatoria de $n = 81$ individuos. Esto significa que cada muestra se divide en cuatro partes iguales y es utilizada en cuatro pruebas diferentes. Además, cada prueba es realizada en una mezcla de $27$ muestras.
Esta metodología se basa en una técnica de construcción de códigos correctores de errores descrita en el recuadro2. Una de sus grandes ventajas es que si hay un solo individuo infectado en la muestra, la composición de la mezcla permite identificar al individuo con certeza. Sin embargo, si más de una persona está infectada, se debe realizar una segunda etapa de pruebas.
Examinemos el ejemplo ruandés en el caso $n = 81 = 3^4$. Sabiendo que el número $X$ de individuos infectados en la muestra tiene una distribución binomial de parámetros $n = 81$ a $p$, tenemos
\[\text{Pr}(X ≤1)=(1 – p)^{81}+81p(1–p)^{80}.\]
Esta metodología es interesante si la probabilidad de que $X ≤ 1$ es grande. Pero, por ejemplo, para asegurar que $\text{Pr}(X ≤ 1) ≥ 0{,}95$, debemos tener $p ≤ 0{,}44\%$, es decir, la prevalencia de la enfermedad debe ser baja. Con una prevalencia del 1%, tenemos $\text{Pr}(X ≤ 1) = 0{,}806$ y casi en el 20 % de los casos habrá que utilizar una segunda etapa. Sin embargo, para el 1 % de la prevalencia, tenemos
\[\text{Pr}(X=2)=\pmatrix{81 \\ 2}p^2(1-p)^{79}=0{,}146,\]
y así $\text{Pr}(X ≤ 2) = 0{,}952$.
Los costos se pueden controlar fácilmente, si escogemos inteligentemente la manera de llevar a cabo la segunda etapa, en el caso de que haya más de una persona infectada. Por ejemplo, todos los casos en los cuales $X = 2$ cumplen con la siguiente propiedad (ver la figura 4, en la cual mostramos, en el caso de $m = 3$, los cortes transversales cuya prueba es positiva):
(P) Para cualquier valor de $i \in \{1, \ldots, m\}$, existen como máximo dos secciones transversales del hipercurbo de la forma $x_i = s$ y $x_i = t$ que dan como resultado una prueba positiva. Además, existe al menos un valor para i para el cual existen exactamente dos secciones transversales del hipercurbo que resultan en pruebas positivas.

Figura 4
El hipercubo discreto $\{ 0, 1, 2\}^3$ y las tres posibilidades para dos individuos infectados: en la misma línea recta paralela a un eje (izquierda), en vértices opuestos de un cuadrado en un plano (centro) o en vértices opuestos de un cubo (derecha). En cada caso, los trozos que dan positivo se identifican en rojo, verde o azul con las mismas convenciones de color que en la figura 3.
Si $k$ es el número de valores de $i \in \{ 1, \ldots, m \}$ para los cuales tenemos dos pruebas positivas de la forma especificada en (P), la cantidad de pruebas adicionales necesarias para identificar a todos los individuos infectados se muestra en la siguiente tabla.
| $k$ | Número de pruebas adicionales |
| 1 | 0 |
| 2 | 4 |
| 3 | 8 |
| 4 | 16 |
Si la propriedad (P) no se satisface, todos los individuos en las secciones transversales que dieron un resultado positivo tienen que ser evaluados. Esto significa que hay que hacer como máximo $81$ pruebas adicionales. Al final, el costo relativo total será igual a $100 \times 17/81 ≈ 21\%$.
Perspectivas
La búsqueda de algoritmos adaptados a la lucha contra el coronavirus está en auge. Recientemente, un equipo de investigación israelí desarrolló e implementó en laboratorio un algoritmo que utilizaremos como un ejemplo. Este algoritmo consiste en realizar $48$ pruebas sobre la misma muestra aleatoria de tamaño $8 \times 48 = 384$. Cada muestra individual se divide en seis partes iguales. Cada una de las pruebas se basa en la mezcla de $48$ de estas partes, una parte representa un individuo. Por tanto, cada sujeto está presente en seis pruebas diferentes. En el laboratorio se programó un robot para preparar las $48$ mezclas. El algoritmo puede identificar hasta cuatro personas infectadas. Esto significa que se necesitan ocho veces menos pruebas que el número de individuos. Como ya se mencionó antes, cuanto menor sea el porcentaje de personas infectadas, mejor será el rendimiento del algoritmo.
Por supuesto, otras consideraciones entran en juego al desarrollar una prueba estadística. Para hacerlo más simple, implícitamente hemos asumido aquí que la prueba empleada es infalible. En la práctica, incluso los mejores procedimientos pueden generar falsos positivos o falsos negativos. La sensibilidad y especificidad de las pruebas son elementos importantes a tener en cuenta al momento de recomendar su implementación, igual que su viabilidad en términos de tiempo, costo y complejidad de las manipulaciones.
Creación de un algoritmo no adaptativo
Nuestro objetivo es crear un algoritmo no adaptativo para hacer pruebas en un grupo de personas. Representaremos este algoritmo mediante una tabla con $T$ filas y $n$ columnas, o equivalentemente mediante una matriz de dimensión $T \times n$ con entradas iguales a $0$ o $1$. La $i^a$ fila de la matriz representa la $i^a$ prueba. Las entradas iguales a $1$ en la $j^a$ columna representan las pruebas en las que participa el $j^o$ individuo. Por lo tanto, $m_{ij} = 1$ si el $j^o$ individuo toma parte en la $i^a$ prueba y $0$, si no.
Supongamos que $X$ es un vector de longitud $n$ que representa al grupo que vamos a examinar: su $i^a$ coordenada, $x_i$, es igual a $1$ si el $i^o$ individuo está infectado y $0$ en caso contrario. Podemos pensar a $X$ como una palabra de longitud $n$ y sus coordenadas iguales a $1$ como errores en la transmisión de una palabra inicial $X_0$, cuyas coordenadas habrían sido $0$. Los algoritmos de códigos correctores de errores se utilizan para corregir errores que puedan haber ocurrido en transmisión de $X_0$, lo que corresponde a la identificación de las coordenadas $x_i$ del vector $X$, que son iguales a $1$, lo que es exactamente nuestro objetivo. Como se muestra en el ejemplo, un algoritmo de corrección de errores sólo puede corregir un número máximo de errores, $k$, el cual es un valor predeterminado.
La matriz $M$ es la matriz de código. Una condición suficiente para que el código pueda corregir $k$ errores es que la matriz sea $k$-disjunta. Definamos esta noción. Queremos evitar la siguiente situación: si los individuos $j_1, \ldots , j_k$ (no necesariamente distintos) están infectados, entonces un $j_{k+1}^o$ individuo infectado pasa desapercibido. Escoger la columna $j$ (es decir, el $j^o$ individuo), es lo mismo que escoger el subconjunto $A_j$ de $\{1, \ldots, T \}$ de sus entradas que son iguales a $1$ (es decir, todas las pruebas en las que este individuo toma parte). Si los individuos $j_1, \ldots, j_k$ están infectados, entonces todas las pruebas correspondientes a la unión $A_{j_1} \cup \cdots \cup A_{j_k}$ serán positivas. Para que la $j_{k+1}^{a}$ persona infectada no pase desapercibida, $A_{j_{k +1}}$ no debe incluirse en $A_{j_1} \cup \cdots \cup A_{j_k}$. La matriz $M$ es $k$-disjunta si esto es válido para todos los $j_1, \ldots, j_k$ y todos los $j_{k+1}$ distintos de $j_1, \ldots, j_k$. La matriz $12 \times 81$ correspondiente al ejemplo anterior usado en Ruanda sería una matriz 1-disjunta.
Hay dos tipos principales de métodos para construir matrices $k$-disjuntas. El primero es probabilístico: generamos de manera aleatoria matrices, cuyas entradas son $1$ con la probabilidad $q$ y $0$ en caso contrario. Para $n$, $T$ y $k$ bien elegidos la probabilidad de que la matriz sea $k$-disjunta no es de cero; por el método de ensayo y error terminamos por generar una matriz $k$-disjunta.
El segundo método, algebraico, está tomado de la teoría de los códigos correctores de errores de Reed-Solomon. Este método permite construir matrices $M$, en las cuales todas las filas tienen el mismo número $m$ de entradas diferentes de cero y todas las columnas tienen el mismo número $c$ de entradas que no son cero. Todas las pruebas se realizan en subgrupos de tamaño $m$ y cada muestra individual se divide en $c$ partes que se incluirán en $c$ pruebas diferentes.
- La aproximación se justifica si la población es mucho más grande en comparación con el tamaño de los grupos. ↩
- Véase también https://accromath.uqam.ca/wp-content/uploads/2020/02/Codes.pdf para una introducción a los códigos correctores de errores. ↩