
Soucieux de protéger l’environnement en diminuant son empreinte carbone, Maxime décide d’adopter le transport en commun pour ses déplacements quotidiens. À partir de la fenêtre de son bureau donnant directement sur l’arrêt d’autobus, Maxime s’amuse à noter l’heure de passage des autobus, mais constate que lorsqu’il se rend finalement à l’arrêt, son temps d’attente est plus long. L’Univers s’est-il ligué contre Maxime pour tester ses convictions écologiques? Nous verrons que Maxime vient plutôt d’observer un exemple du paradoxe du temps d’attente connu de façon générale sous le vocable du paradoxe de l’inspection.
Les autobus sont-ils plus lents quand je les prends?
Dans le cadre du jour de la terre, le 22 avril, Maxime a décidé d’observer les passages des autobus de 15h à 16h. Dans la ville de Maxime, les lignes d’autobus portent des noms de fleurs, et pour la ligne des Œillets qu’il utilise normalement pour rentrer à la maison, il note des passages à 15h03, 15h21, 15h23, 15h27, 15h28, 15h31, 15h37, 15h40, 15h51 et 15h59. À partir de ces données, il calcule les écarts entre chaque passage d’autobus, soit: 18, 2, 4, 1, 3, 6, 3, 11 et 8. Le temps moyen entre le passage de deux autobus est donc de 6,22 minutes cette journée-là avec un écart-type de 5,43 minutes, ce qui est compatible avec l’horaire annoncé d’un passage aux six minutes.
Maxime quitte le travail à une heure uniformément répartie entre 16h00 et 17h00. Étant donné que les autobus passent aux 6 minutes environ, il prévoit d’attendre 3 minutes en moyenne. Pourtant, il passe plus de 5 minutes à attendre, et c’est souvent le cas. Maxime trouve un peu frustrant d’être aussi malchanceux! Les chauffeurs ralentissent-ils lorsque Maxime se présente à l’arrêt?
Quel autobus Maxime prendra-t-il?
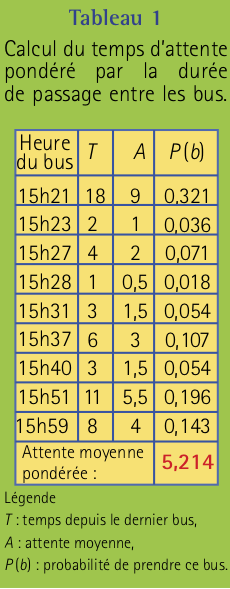 C’est en discutant avec son meilleur ami Jean-Michel, un éternel optimiste au grand cœur, que Maxime réalise qu’il n’est peut-être pas victime de malchance. Jean-Michel lui demande: « Si tu étais parti entre 15h04 et 15h59 aujourd’hui, quel autobus aurais-tu pris? » Pour simplifier nos calculs, arrondissons à la minute près et considérons que Maxime est sorti à un temps uniforme entre 15h04 et 15h59. S’il arrive à la même heure qu’un bus ou avant, il peut prendre ce bus. Comme il y a 56 minutes dans cet intervalle, il a une probabilité égale d’arrivée à chacune des minutes. La probabilité de prendre un bus arrivé k minutes après le bus précédent est donc de k/56.
C’est en discutant avec son meilleur ami Jean-Michel, un éternel optimiste au grand cœur, que Maxime réalise qu’il n’est peut-être pas victime de malchance. Jean-Michel lui demande: « Si tu étais parti entre 15h04 et 15h59 aujourd’hui, quel autobus aurais-tu pris? » Pour simplifier nos calculs, arrondissons à la minute près et considérons que Maxime est sorti à un temps uniforme entre 15h04 et 15h59. S’il arrive à la même heure qu’un bus ou avant, il peut prendre ce bus. Comme il y a 56 minutes dans cet intervalle, il a une probabilité égale d’arrivée à chacune des minutes. La probabilité de prendre un bus arrivé k minutes après le bus précédent est donc de k/56.
C’est ainsi que Maxime réalise que plus le temps d’attente entre deux autobus est long, plus il a de chance d’arriver à l’arrêt de bus pendant cet intervalle de temps. Avec son raisonnement initial, Maxime prévoyait un temps moyen d’attente égale à la moitié de la durée moyenne entre deux bus, soit 6,22/2 = 3,11 minutes selon les données collectées. En tenant compte qu’il a plus de chance de prendre un bus tardif, la moyenne pondérée par la probabilité de prendre chaque bus est plutôt de 5,21 minutes.
L’appartement de Jean-Michel se trouve à côté du terminus d’autobus où le départ des autobus se produit vraiment à toutes les six minutes. Lorsqu’il part de chez Jean-Michel, le temps d’attente de Maxime correspond davantage aux trois minutes auxquelles il s’attendait. La constance dans l’horaire aurait-elle un effet bénéfique?
Les mathématiques pour dénouer le problème
Peut-on déterminer mathématiquement le temps moyen d’attente? Maxime a observé des temps entre les passages d’autobus. Notons par \(X_1, X_2, …\) ces temps entre les bus en minutes. Supposons qu’un bus est passé à midi et que \(X_1\) est le temps avant le passage du premier bus en après-midi. Nous supposerons que les temps entre les bus sont indépendants et suivent une même distribution avec densité \(f(x).\) Ainsi, en comptant à partir de midi, l’autobus \(n\) passe à l’heure
\[S_n=\sum_{i=1}^{n} X_1.\]
Une telle séquence de variables aléatoires indicées par le temps est appelée un processus stochastique. Ces variables sont représentées à la figure 1.

Lorsque Maxime se rend à l’arrêt au temps t, il vient de manquer l’autobus \(N(t)=\max \{n:S_n ≤t \}.\) En fait, N(t) est une variable aléatoire qui représente le nombre d’autobus dans [0, t]. On appelle N(t) un processus de renouvellement (voir l’encadré à cet effet).
Dans son raisonnement initial, Maxime croyait qu’il attendrait en moyenne la moitié du temps de \(X_t,\) mais son attente est plutôt liée à \(X_{N(t)+1}.\) L’indice aléatoire de la durée entre les autobus fait toute la différence. Il permet de représenter le phénomène déjà observé à l’effet que Maxime a plus de chance de monter dans les bus plus tardifs. De façon générale, une variable aléatoire \(N\) positive et à valeurs entières est un temps d’arrêt pour la suite des variables aléatoires \(\{X_1, X_2,\ldots \}\) si l’événement \(\{N = n\}\) est entièrement déterminé par \(\{X_1, X_2,\ldots, X_n\}\) et est indépendant de \(\{X_{n+1}, X_{n+2},\ldots \}.\) C’est le cas ici pour \(N = N (t) + 1\) puisqu’il suffit de savoir le temps de passage des \(N(t)+1\) premiers bus pour savoir que \(t\) se trouve entre \(S_{N(t)}\) et \(S_{N(t)+1}.\)
Le problème du temps d’attente est un exemple de processus de renouvellement. Dans le cadre d’un tel processus, on s’intéresse aux différents temps dans l’intervalle associé à t, notamment:
- La durée de vie totale:
\[X_{N(t)+1}= S_{N(t)+1} – S_{N(t)}.\] - L’âge du processus:
\[V(t) = t – S_{N(t)}.\] - Le temps de vie résiduelle qui correspond également au temps d’attente:
\[W(t) = S_{N(t)+1}- t.\]
Pour Maxime, c’est le temps d’attente W(t) qui compte. Nous allons calculer sa valeur moyenne, également appelée espérance de W(t) et notée par E{W(t)}.
En utilisant la définition présentée ci-bas, on peut écrire
\[E\{W(t)\} = E\{S_{N(t)+1}–t\} = E\{S_{N(t)+1}\}–t.\]
Ceci signifie que l’espérance du temps d’attente dépend en fait de l’espérance du temps de passage du prochain bus, soit \(E\{S_{N(t)+1}\},\) pour lequel plusieurs résultats apparaissent dans la littérature. En particulier, l’équation de Wald, dont une preuve élégante se trouve dans un encadré, nous assure qu’en autant que la durée du passage entre deux bus ait une espérance strictement positive et finie, nous aurons que:
\[E\{S_{N(t) + 1}\}= E(X_1)E\{N(t) + 1\},\]
où on utilise \(E(X_1)\) pour représenter la moyenne commune à tous les \(X_n\). Le calcul du temps moyen d’attente de Maxime se voit ainsi transformé en un problème lié au nombre moyen de bus ayant passé à une certaine heure. Or, cette question a également été largement étudiée.
Processus de renouvellement
Un processus de renouvellement est une suite de variables aléatoires positives ayant la même moyenne et variance. Il pourrait s’agir par exemple de la durée de vie des composantes, disons une ampoule tombant en panne au temps \(S_1=X_1\), puis remplacée par une autre tombant en panne à son tour au temps \(S_2 = X_1+X_2,\) et ainsi de suite, d’où l’appellation processus de renouvellement. La variable \(S_n = \sum_{i=1}^{n} X_i\) représente ainsi le temps du nième renouvellement. Le domaine de l’assurance et la théorie des files d’attente, entre autres, comptent de nombreuses applications de ces processus.
La formule exacte pour l’espérance de \(N (t )+1\) dépend de \(t\). En effet, si \(t\) est petit, il se pourrait ou non qu’il soit possible d’observer plus d’un bus passer selon la loi associée à \(f(x)\) (fonction de densité des \(X_i\)). Au fur et à mesure que le temps passe, l’effet de ces premiers bus s’estompe. Comme c’est souvent le cas en statistique, les calculs asymptotiques pour \(t \to \infty\) sont plus simples. Ainsi, l’évaluation de \(E\{W(t)\}\) est élaborée dans un cadre asymptotique. Dans ce cas-ci, on suppose que \(t \to \infty\), ce qui ne sera jamais parfaitement exact, mais qui nous donnera une excellente approximation pour un grand nombre d’autobus. Dans des publications classiques, il est prouvé que
\[E\{N(t)\}\approx \frac{t}{\mu} + \frac{1}{2} \left ( \frac{\sigma^2}{\mu^2}-1 \right ) \: \text{lorsque} \: t \to \infty,\]
où \(\mu=E(X_1)\) et \(\sigma^2=\text{var}(X_1)\) sont la moyenne et la variance des temps entre les passages d’autobus consécutifs. En combinant les équations précédentes, on trouve:
\[\begin{array} {r c l} E\{W(t)\}&=&E(X_1)E{N(t)+1}−t \\ & \approx & \displaystyle \mu \left \{ \frac{t}{\mu} + \frac{1}{2} \left ( \frac{\sigma^2}{\mu^2}-1 \right ) +1 \right \} -t \\ & = & \displaystyle \frac{\sigma^2}{2 \mu} + \frac{\mu}{2} = \frac {\mu}{2} \left ( 1+ \frac{\sigma^2}{\mu^2} \right ). \end{array}\]
Cette dernière expression permet de confirmer mathématiquement que le temps d’attente de Maxime sera toujours plus long que \(\mu/2,\) sauf si les autobus sont précisément à l’heure (lorsque la variance du temps entre les bus est 0). Ces résultats sont conformes avec les observations de Maxime, y compris le fait que le temps d’attente réel au terminal est très près de\(\mu/2.\)
En utilisant le coefficient de variation \(c_v = \sigma/\mu\) comme mesure de dispersion relative, on peut également écrire
\[E\{W(t)\}\approx \frac{\mu}{2}(1+c_v^2), \]
qui montre que l’augmentation du temps d’attente moyen suit une courbe parabolique en fonction de \(c_v.\)
Intuitivement, il serait raisonnable que le temps moyen entre le bus emprunté par Maxime et le bus précédent soit égal à deux fois son temps d’attente. On peut confirmer cette intuition en calculant mathématiquement la valeur moyenne de \(V(t).\) Même si les résultats asymptotiques pour \(E\{V(t)\}\) sont beaucoup plus difficiles à obtenir (voir par exemple les travaux d’Adès et Malhamé), leur expression asymptotique est identique à celle obtenue pour \(E\{W(t)\}.\) On a donc effectivement
\[\begin{array}{r c l} E\{X_{N(t)+1}\}&=&E\{V(t)\}+E\{W(t)\} \\ & \approx & (1+c_v^2) \mu \: \text{lorsque} \: t \to \infty. \end{array} \]
Cette dernière espérance démontre la dominance stochastique de \(X_{N(t) + 1}\) sur le temps de passage entre deux bus, à savoir que
\[ E\{X_{N(t)+1}\} \geq E(X_1) = \mu,\]
avec une inégalité stricte dès que la variance de \(X_1\) est non-nulle. Clairement, la moyenne de \(X_{N(t)+1}\) est plus grande que les autres intervalles qui le précèdent. Voilà un résultat paradoxal d’où le nom paradoxe du temps d’attente ou de l’inspection. Il s’agit là d’une conséquence du fait déjà observé à l’effet que le point t a bien plus de chance de tomber dans un long intervalle que dans un petit.
Rien ne sert de courir il faut que le bus arrive à point
Maxime a donc trouvé mathématiquement qu’en plus de leur fréquence, la constance des bus a une influence sur le temps d’attente des usagers. À partir du bureau, Maxime peut choisir l’une des trois lignes suivantes:
- La ligne des Œillets pour laquelle il a déjà collecté des données,
- La ligne des Ancolies,
- La ligne des Roses.
Alors que la ligne des Œillets offre un service aux 6 minutes, les lignes des Ancolies et des Roses ont un service aux 8 minutes. Maxime a pris l’habitude d’utiliser la ligne des Œillets puisque c’est la ligne la plus fréquente.
Pendant quelques semaines, Maxime observe les bus et s’attarde à leur ponctualité. Il constate des variations substantielles du temps de passage pour les lignes des Œillets et des Ancolies. La ligne des Roses s’avère toutefois beaucoup plus ponctuelle avec des temps entre les bus de 8 minutes plus ou moins 30 secondes.
Comme il n’est pas facile d’obtenir un calcul exact pour ces temps moyens de passage, et dans le but de mieux comprendre ses options, Maxime décide de simuler 1 000 fois ses déplacements avec un ordinateur. Étant donné ses observations, il génère le passage des autobus toute la journée selon des familles de lois pour lesquelles il trouve un générateur de nombres:
- Ligne des Œillets: loi exponentielle de moyenne 6 minutes (et donc d’écart-type 6 minutes),
- Ligne des Ancolies: loi exponentielle de moyenne 8 minutes (et donc d’écart-type 8 minutes),
- Ligne des Roses: loi uniforme entre 7,5 et 8,5 minutes (et donc d’écart-type \(\sqrt{1/12}\) minute).

Pour chacune des 1 000 journées, il génère les temps de passage des trois lignes de bus pour l’après-midi. Il simule également l’heure à laquelle il se présente à l’arrêt, selon une loi uniforme entre 16h et 17h. Il note la durée de son attente pour les trois bus toutes ces journées. La figure 2 présente les boîtes à moustache des temps d’attente générés pour les trois lignes. La partie centrale de ces boîtes va du premier quartile \(Q_1\) au troisième quartile \(Q_3\) des données et la ligne centrale représente la médiane \(Q_2\). Des lignes appelées moustaches dont la longueur maximale est \(1,5(Q_3–Q_1)\) s’étendent de chaque côté jusqu’à la valeur non extrême la plus éloignée. Toute valeur excédant cette longueur maximale est marquée d’un point. Les boîtes à moustache permettent de comparer la distribution de plusieurs jeux de données en un coup d’œil puisqu’elles présentent côte-à-côte plusieurs quantiles des données. Cette représentation graphique est due à Tukey.
Globalement, c’est le parcours des Roses qui offre le temps d’attente le plus court. On calcule en effet une attente moyenne de 3,92 minutes pour la ligne des Roses, mais de 6,37 minutes pour la ligne des Œillets et de 8,12 minutes pour le parcours des Ancolies. Selon la formule asymptotique, pour \(t \to \infty,\) trouvée précédemment, ces temps moyens d’attente devraient être de 4,0052, 6 et 8 minutes respectivement. Les valeurs trouvées par simulation sont compatibles avec ce résultat théorique. Maxime simule les parcours des autobus à partir de midi, mais part entre 16 et 17 heures. Avec environ une trentaine de bus ayant déjà passé, les résultats asymptotiques trouvés sont très près des valeurs empiriques découlant de la simulation.
Même si les autobus du parcours des Roses sont moins fréquents que ceux de la ligne des Œillets, leur régularité leur confère un temps moyen d’attente moindre. À ce sujet, Maxime a également noté dans sa simulation lequel des trois parcours il emprunterait en utilisant le premier autobus disponible après le temps t. Ces résultats se trouvent à la figure 3.
Grâce à sa régularité, le parcours des Roses est celui qui arrive le plus souvent en premier, soit 43,5 % du temps. À l’aide de la simulation, Maxime a réussi à confirmer que le temps d’attente ne dépend pas seulement du temps moyen entre deux passages de bus, mais aussi de leur ponctualité.
Empreinte carbone
Maxime décide de prendre le transport en commun plutôt que d’utiliser la voiture afin de réduire son empreinte carbone. En fait, l’empreinte carbone est la quantité de gaz à effet de serre qu’une personne émet, et notons qu’il y a consensus dans le milieu scientifique à l’effet que les gaz à effet de serre émis par l’activité humaine sont la cause principale des changements climatiques.
Même si un litre d’essence ne pèse que 0,727 kg, sa combustion produit 2,29 kg de CO2 (l’oxygène puisé dans l’air est plus lourd que le carbone de l’essence). Il suffit donc de brûler 437 litres d’essence pour produire une tonne de gaz à effet de serre, soit de 7 à 10 plein d’essence selon le véhicule. Une voiture qui consomme 10 litres aux 100 km produit donc une tonne de CO2 à tous les 4370 km, et environ 45 tonnes pendant sa vie utile.
En termes absolus, l’autobus que prend Maxime produit plus de CO2, mais en divisant par le nombre d’usagers, l’empreinte attribuée à chacun est bien moindre, d’où l’intérêt des transports collectifs. Les transports électrifiés comme le métro sont encore plus écologiques, en particulier au Québec où la production et la distribution de l’électricité émet très peu de carbone étant donné la grande proportion d’énergie de source hydraulique.
Au-delà des bus
Au-delà des temps d’attente à l’arrêt de bus, le paradoxe de l’inspection se produit également dans d’autres situations, en voici quelques-unes:
Génétique
En génétique, les chercheurs tentent d’identifier la position des mutations génétiques liées à certaines maladies. Comme les gènes sont découpés en plusieurs séquences de différentes longueurs, Jeanpierre (2008) (voir Pour en savoir plus!) constate que le paradoxe de l’inspection rend les longues séquences plus susceptibles de contenir des gènes d’intérêt. De même, les fluctuations aléatoires de l’ADN ont également une plus grande chance de survenir dans les séquences plus longues.
Négociation de titres
En modélisant la négociation des titres boursiers en ligne, Inoue et coll. (2010) (voir Pour en savoir plus!) s’intéressent au temps entre l’observation du prix sur les marchés financiers et le prochain changement de prix. En assumant que le processus stochastique modélisant la variation de prix soit un processus de renouvellement, ils déduisent la distribution du temps d’attente du processus et sa moyenne. Ils constatent que le temps d’attente est supérieur au temps moyen entre deux changements de prix et attribuent ce phénomène au paradoxe de l’inspection. En d’autres termes, le temps moyen d’attente est plus long que la moitié de la durée moyenne entre les changements de prix.
Traitement du cancer
Crawford et coll. (2002) (voir Pour en savoir plus!) constatent un autre type de paradoxe lié au temps d’attente : dans le traitement du cancer, les patients qui attendent le plus pour voir un spécialiste ont une meilleure chance de survie. Ils expliquent ce paradoxe par le fait que les patients plus à risque attendent moins longtemps car la sévérité de leur situation est transmise aux spécialistes afin qu’ils les rencontrent sans délai.
Preuve de l’équation de Wald1
Pour un temps d’arrêt générique \(N,\) l’équation de Wald affirme que l’espérance des temps de panne est égale au nombre moyen de renouvellements fois la durée moyenne des renouvellements, soit
\[E(S_N) = E(X_1)E(N).\]
Afin de prouver cette équation, on définit d’abord la variable indicatrice \(I_n\) qui égale 1 si \(n ≤ N\) et 0 sinon. On peut ainsi écrire
\[\begin{array} { r c l} E(S_N) & = & \displaystyle E \left (\sum_{n=1}^{N} X_n \right ) = E \left (\sum_{n=1}^{\infty} X_n I_n \right ) \\ & = & \displaystyle \sum_{n=1}^{\infty} E(X_n I_n). \end{array}\]
Lorsque deux variables aléatoires sont indépendantes, l’espérance de leur produit égale le produit de leur espérance. On aimerait bien que \(I_n\) soit indépendante de \(X_n,\) or c’est bien le cas puisque la valeur de \(I_n\) est dictée par \(N ≥ n,\) qu’on peut déterminer dès que \(S_{n −1}< t.\) Bref, \(I_n\) dépend de \(X_1,\ldots, X_{n −1},\) mais pas de \(X_n,\) ce qui donne
\[E(S_N)=\sum_{n=1}^{\infty}E(X_n)E(I_n)=E(X_1)\sum_{n=1}^{\infty}E(I_n),\]
où on utilise \(E(X_1)\) pour représenter la moyenne commune à tous les \(X_n.\) Comme \(E(I_n)= P(N ≥ n),\) on peut ensuite remarquer que
\[\begin{array} { r c l} \displaystyle \sum_{n=1}^{\infty}E(I_n) &=& \displaystyle \sum_{n=1}^{\infty}P(N ≥n)= \sum_{n=1}^{\infty}\sum_{i=n}^{\infty}P(N =i) \\ &=& \displaystyle \sum_{i=1}^{\infty}\sum_{n=1}^{i}P(N =i)=\sum_{i=1}^{\infty}iP(N =i)=E(N) \end{array}\]
en changeant l’ordre des deux sommes de façon similaire à un changement de l’ordre d’intégration. On obtient ainsi l’expression initiale pour l’équation de Wald, mais avec \(N = N (t )+1\) comme temps d’arrêt.
Pour en s\(\alpha\)voir plus !
- Adès M., Malhamé R. P., Asymptotic Characterization of Wald Type Vector Cumulative Processes. Les Cahiers du GERAD G-2000-39, Août 2000.
- Adès M., Malhamé R. P., Asymptotics of the Moments of Cumulative Vector Renewal Reward Processes: The Case N(t). Les Cahiers du GERAD G-94-32, Révisé 1997.
- Crawford S.C., Davis J.A., Siddiqui N.A., de Caestecker L., Gillis C.R., Hole D., Penney G.,The waiting time paradox: population based retrospective study of treatment delay and survival of women with endometrial cancer in Scotland. British Medical Journal, Vol. 325, p. 196, Juillet 2002.
- Inoue J., Sazuka N. & Scalas E., On-line trading as a renewal process: Waiting time and inspection paradox. Papers 1007.3347, arXiv.org, 2010.
- Jeanpierre M., The Inspection Paradox and Whole-Genome Analysis, Advances in Genetics, Vol. 64, 2008.
- L’équation de Wald est une conséquence de l’identité de Wald. ↩