
Comment améliorer une solution imparfaite à un problème complexe? Et si on s’inspirait de la nature pour faire évoluer les solutions?
L’inspiration de la nature
En 1859, le naturaliste Charles Darwin a publié son célèbre ouvrage L’origine des espèces, qui présentait une théorie visant à expliquer le phénomène de l’évolution. Cette théorie révolutionnaire a provoqué plusieurs débats à l’époque mais elle est maintenant largement acceptée. Environ 100 ans plus tard, elle a inspiré le professeur John Holland qui a tenté d’implémenter artificiellement des systèmes évolutifs basés sur le processus de sélection naturelle. Ces travaux ont ensuite mené aux algorithmes génétiques, qui sont maintenant utilisés pour obtenir des solutions approchées pour certains problèmes d’optimisation difficiles.
 Les travaux sur l’évolution des espèces vivantes du naturaliste et paléontologue anglais Charles Darwin (1809-1882) ont révolutionné la biologie. Dans son ouvrage intitulé L’Origine des espèces paru en 1859, Darwin présente le résultat de ses recherches. Darwin était déjà célèbre au sein de la communauté scientifique de son époque pour son travail sur le terrain et ses recherches en géologie. Ses travaux s’inscrivent dans la foulée de ceux du naturaliste français Jean-Baptiste de Lamarck (1744-1829) qui, 50 ans plus tôt, avait émis l’hypothèse que toutes les espèces vivantes ont évolué au cours du temps à partir d’un seul ou de quelques ancêtres communs. Darwin a soutenu, avec Alfred Russel Wallace (1823-1913), que cette évolution était due au processus dit de la « sélection naturelle ».
Les travaux sur l’évolution des espèces vivantes du naturaliste et paléontologue anglais Charles Darwin (1809-1882) ont révolutionné la biologie. Dans son ouvrage intitulé L’Origine des espèces paru en 1859, Darwin présente le résultat de ses recherches. Darwin était déjà célèbre au sein de la communauté scientifique de son époque pour son travail sur le terrain et ses recherches en géologie. Ses travaux s’inscrivent dans la foulée de ceux du naturaliste français Jean-Baptiste de Lamarck (1744-1829) qui, 50 ans plus tôt, avait émis l’hypothèse que toutes les espèces vivantes ont évolué au cours du temps à partir d’un seul ou de quelques ancêtres communs. Darwin a soutenu, avec Alfred Russel Wallace (1823-1913), que cette évolution était due au processus dit de la « sélection naturelle ».
Comme il naît beaucoup plus d’individus de chaque espèce qu’il n’en peut survivre, et que, par conséquent, il se produit souvent une lutte pour la vie, il s’ensuit que tout être, s’il varie, même légèrement, d’une manière qui lui est profitable, dans les conditions complexes et quelquefois variables de la vie, aura une meilleure chance pour survivre et ainsi se retrouvera choisi d’une façon naturelle. En raison du principe dominant de l’hérédité, toute variété ainsi choisie aura tendance à se multiplier sous sa forme nouvelle et modifiée.
– Charles Darwin, 1859 Introduction à L’Origine des espèces.
Les éléments de base d’un algorithme génétique
Afin de comprendre l’analogie entre le processus de sélection naturelle et un algorithme génétique, rappelons tout d’abord les mécanismes les plus importants qui sont à la base de l’évolution.
- L’évolution se produit sur des chromosomes qui représentent chacun des individus dans une population.
- Le processus de sélection naturelle fait en sorte que les chromosomes les mieux adaptés se reproduisent plus souvent et contribuent davantage aux populations futures.
- Lors de la reproduction, l’information contenue dans les chromosomes des parents est combinée et mélangée pour produire les chromosomes des enfants (« croisement »).
- Le résultat du croisement peut à son tour être modifié par des perturbations aléatoires (mutations).
Ces mécanismes peuvent être utilisés pour spécifier un algorithme génétique tel que celui décrit dans l’encadré ci-dessous.
Un algorithme génétique
- Construire une population initiale de N solutions.
- Évaluer chacun des individus de la population.
- Générer de nouvelles solutions en sélectionnant les parents de façon proportionnelle à leur évaluation. Appliquer les opérateurs de croisement et de mutation lors de la reproduction.
- Lorsque N nouveaux individus ont été générés, ils remplacent alors l’ancienne population. Les individus de la nouvelle population sont évalués à leur tour.
- Si le temps alloué n’est pas dépassé (ou le nombre de générations maximal n’est pas atteint), retourner à l’étape 3.
Pour adapter un algorithme génétique à un problème d’optimisation combinatoire, il suffit alors de spécialiser certaines composantes à la structure particulière de ce dernier. En général, les décisions portent sur les aspects suivants :
Codage des solutions : il faut établir une correspondance entre les solutions du problème et les chromosomes.
Opérateurs génétiques : il faut définir des opérateurs de croisement et de mutation pour les chromosomes.
Évaluation des chromosomes : la mesure d’adaptation des chromosomes à leur environnement est donnée par une fonction qui est calculée par un processus plus ou moins complexe.
Il existe plusieurs moyens pour mettre en œuvre certains des mécanismes importants d’un algorithme génétique. Par exemple, la sélection des parents peut s’effectuer de diverses façons. Dans une population \(P = \{x_1, x_2, \ldots, x_N\}\) où la mesure d’adaptation d’un individu est évaluée par une fonction ƒ, l’opérateur classique consiste à associer à chaque individu \(x_i\) une probabilité \(p_i\) d’être sélectionné proportionnelle à la valeur de f pour cet individu, c’est-à-dire :
\[ P_i = \frac{f(x_i)}{\sum\limits_{j\in P} f(x_j)}.\]
En pratique, on utilise souvent d’autres méthodes de sélection pouvant se para- métrer plus facilement. Ainsi, dans la sélection par tournoi, un ensemble d’individus est sélectionné aléatoirement, dont les meilleurs éléments seulement sont retenus. Pour choisir deux parents, on peut donc sélectionner aléatoirement 5 individus et ne garder que les deux meilleurs. Dans d’autres méthodes, les individus sont ordonnés selon leur valeur pour la fonction f, et la sélection s’effectue aléatoirement selon le rang occupé par chaque individu. On utilise alors une distribution biaisée en faveur des individus en tête de liste.
Un autre mécanisme important est le mode de remplacement des individus de la population. Dans le modèle original, chaque population de N individus est totalement remplacée à chaque génération. D’autres stratégies « élitistes » font en sorte d’assurer à chaque génération la survie des meilleurs individus de la population. C’est le cas entre autres des modèles « stationnaires » où un nombre restreint d’individus est remplacé à chaque génération. Dans ce cas, on ajoute souvent des mécanismes supplémentaires empêchant l’ajout d’individus identiques (doublons) dans la population. Des implantations plus évoluées existent également pour des architectures parallèles.
 Représentation des solutions et opérateurs génétiques
Représentation des solutions et opérateurs génétiques
Les premiers algorithmes génétiques utilisaient tous une représentation binaire où chaque solution s est codée sous la forme d’une chaîne de bits de longueur n, i.e. \(s[i ] \in \{0, 1\}, \forall i =1, 2, \ldots, n.\) Pour cette représentation, l’opérateur de croisement classique à un point consiste à choisir de façon uniforme une position de coupure aléatoire \(l \in \{1, 2, \ldots, n-1\}.\) Si les parents \(p_1\) et \(p_2\) ont été sélectionnés pour la reproduction, les solutions enfants \(e_1\) et \(e_2\) sont alors construites de la façon suivante :
\[\begin{array}{r c l}e_1[i] &= &p_1[i], \forall i \in\{1, \ldots, l\} \\ e_1[i ] &= &p_2[i ], \forall i \in\{l + 1, \ldots, n\}\\ e_2 [i] &= &p_2[i], \forall i \in\{1, \ldots, l\}\\ e_2 [i ] &= &p_1[i ], \forall i \in\{l + 1, \ldots, n\}.\end{array}\]
Lorsqu’on itère avec d’autres paires de parents, on choisit aléatoirement, pour chaque paire de parents, un nouvel opérateur de croisement à un point. L’opérateur à un point peut se généraliser en sélectionnant k positions aléatoires plu- tôt qu’une seule. Dans ce cas, les enfants sont produits en échangeant l’information chromosomique entre les k points de coupure. En pratique, la valeur k=2 est couramment utilisée. Un autre opérateur très populaire (croise- ment uniforme) utilise une chaîne de bits générée aléatoirement pour engendrer les enfants. Pour chaque position, le choix aléatoire indique quel parent déterminera la valeur des enfants. Des exemples des opérateurs de croisement à un point, à deux points, et uniforme sont illustrés dans les tableaux suivants. Des résultats théoriques et empiriques indiquent que l’opérateur de croisement uniforme donne généralement des résultats supérieurs à ceux produits par les deux autres.

Avec une représentation binaire, on utilise généralement l’opérateur de mutation classique qui consiste à changer aléatoirement un bit pour son complément.
Un exemple : le problème de satisfaisabilité booléenne
Pour certains problèmes, la représentation binaire des solutions est tout à fait intuitive et bien adaptée. C’est le cas par exemple du problème de satisfaisabilité (SAT). Étant donné une expression logique F de n variables booléennes \(x_1,x_2,\ldots,x_n\) (voir encadré) ce problème fondamental (qui est à la base de la théorie de la NP-complétude) consiste à trouver une affectation aux variables de façon à satisfaire F. En établissant les correspondances faux ↔ 0, vrai ↔ 1, on peut représenter chaque solution par une chaîne binaire de longueur n et utiliser les opérateurs génétiques classiques décrits précédemment.
Pour évaluer les solutions, l’expression logique F peut être exprimée comme une conjonction (voir encadré) de m clauses :
\[F= \underset{j=1}\land^m C_j \]
Chaque clause est alors définie par une disjonction de variables booléennes dont certaines sont associées à un opérateur de négation (indiqué par le symbole – ). Pour satisfaire F, il faut donc satisfaire toutes ses clauses. Pour un algorithme génétique, chaque solution peut être simplement évaluée par le nombre de clauses qu’elle satisfait, par exemple noté par f. Si on considère par exemple l’expression suivante pour F
\[ \begin{array}{r c l}F &=&(\bar{x}_1)\land(x_1 \lor x_2)\land(\bar{x}_1\lor x_2 ∨x_3)\\&& \land(x_1 \lor \bar{x}_2 \lor x_3 \lor \bar{x}_4) \\ &&\land(x_1 \lor x_2 \lor \bar{x}_3 \lor x_4 \lor \bar{x}_5 ),\end{array}\]
la solution (1,0,1,0,0) satisfait toutes les clauses sauf la première alors que la solution (0,1,1,0,1) satisfait toutes les clauses et donc l’expression F.
Avec une représentation des chromosomes, une fonction d’adaptation f et des opérateurs de croisement et de mutation, nous avons tous les éléments pour implémenter un algorithme génétique simple pour le problème de satisfaisabilité booléenne. Le processus peut être illustré par le tableau ci-dessous avec un opérateur de croisement uniforme représenté par la chaîne de bits U.

Dans cet exemple simplifié, l’algorithme a produit en six générations une solution qui satisfait l’expression booléenne F (les 5 clauses sont satisfaites pour un individu de la population). Pour une fonction plus complexe comprenant un grand nombre de variables, on utilise des populations plus importantes et laisse la population évoluer lentement vers des solutions de bonne qualité.
Variables booléennes
Opérateurs booléens
Une variable booléenne est une variable qui ne peut prendre que deux valeurs logiques: VRAI ou FAUX. On peut utiliser 1 et 0 pour représenter ces deux valeurs.
Un opérateur booléen est un opérateur qui s’applique sur une ou deux variables booléennes.
La négation d’une variable booléenne x qui est notée \(\bar{x}\) change la valeur de la variable booléenne x.

La conjonction de deux variables x et y, notée \(x \land y,\) prend la valeur 1 si les variables x et y ont toutes deux la valeur 1. Dans les autres cas, elle prend la valeur 0.

La disjonction de deux variables x et y, notée \(x \lor y,\) prend la valeur 1 si au moins l’une des variables a la valeur 1. Elle prend la valeur 0 si les deux variables ont la valeur 0.

Autres exemples
Les algorithmes génétiques ne sont pas applicables qu’aux représentations binaires. Par exemple, le problème classique du commis voyageur (Traveling Salesman Problem ou TSP) consiste à identifier une tournée à coût minimal qui visite chaque ville d’un ensemble à couvrir. Même si une tournée pourrait alors théoriquement être représentée par une chaîne de booléens, on préfère généralement utiliser une représentation plus directe sous forme de permutation. Chaque permutation spécifie alors l’ordre dans lequel sont visitées les villes.
 On doit alors définir des opérateurs de mutation et de croisement pour une représentation sous forme de permutation. Pour la mutation, un simple échange entre deux villes dans une séquence pour- ra faire l’affaire. Par exemple :
On doit alors définir des opérateurs de mutation et de croisement pour une représentation sous forme de permutation. Pour la mutation, un simple échange entre deux villes dans une séquence pour- ra faire l’affaire. Par exemple :
Tournée originale : (Montréal, Rimouski, Saguenay, Val d’Or, Québec, Sherbrooke)
Après mutation : (Montréal, Rimouski, Saguenay, Sherbrooke, Québec, Val d’Or)
Pour le croisement, il est facile de constater que des opérateurs semblables à ceux décrits précédemment ne pourraient préserver la structure de permutation. Plusieurs opérateurs valides ont toutefois été proposés. À titre d’exemple, l’opérateur OX choisit une sous-séquence dans la séquence d’un des parents, et place les villes restantes dans l’ordre défini par l’autre parent. Dans le tableau ci-dessous, deux positions sont choisies aléatoirement afin de définir une sous-séquence chez le premier parent (étape 1). À l’étape 2, les villes restantes sont placées selon l’ordre induit par le deuxième parent.
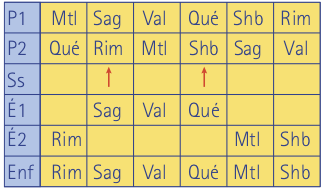
Une fois la représentation et les opérateurs de base définis, on peut simplement évaluer chaque tournée par la distance parcourue, et tous les éléments sont en place pour implémenter un algorithme génétique pour le problème TSP.
Coloration de graphe
Un autre problème classique, celui de coloration de graphe1, est aussi abordable par les algorithmes génétiques.
Pour un graphe \(G = (V, E)\) constitué d’un ensemble de nœuds V et d’arêtes E, un coloriage est une partition de V en k sous-ensembles (couleurs) \(C_1,C_2,\ldots,C_k\) pour lesquels \(u, v \in C_i \Rightarrow (u, v) \notin E,\) i.e. que deux nœuds ne peuvent avoir la même couleur s’ils sont liés par une arête. Le problème de coloration de graphe consiste à trouver un coloriage utilisant un nombre minimal de sous-ensembles. Ce type d’approche permet notamment de résoudre à coût minimum des conflits d’horaire. En pratique, on choisit d’abord une valeur-cible pour k et chaque chromosome constitue une partition de V en k sous-ensembles. Les solutions sont codées sous forme de chaînes en liant l’indice de chaque nœud à l’un des k sous-ensembles.
Par exemple, si on associe \(C_1\) à bleu, \(C_2\) à rouge et \(C_3\) à vert dans le coloriage imparfait de la page précédente, la partition des nœuds associée à cette solution est (1, 2, 3, 2, 3, 2, 1, 2, 3, 1), car les nœuds 1, 7 et 10 sont dans \(C_1,\) les nœuds 2, 4, 6 et 8 dans \(C_2\) et les nœuds 3, 5, et 9 dans \(C_3.\) En définissant la fonction f comme le nombre de fois où la règle du coloriage n’a pas été respectée, on obtient \(f (C_1, C_2, C_3) = 0 + 1 + 1 = 2,\) car on a 0 arête dans \(C_1, 1\) arête dans \(C_2\) (entre les nœuds 2 et 4) et 1 dans \(C_3\) (entre les nœuds 3 et 5).
De façon générale, le problème de coloriage consiste à générer une partition telle que \(f (C_1, C_2, \ldots, C_k) = 0,\) avec un k le plus petit possible. Avec la représentation en chaîne de la partition, il est facile de définir des opérateurs de croisement et de mutation semblables à ceux utilisés pour les représentations binaires. Les résultats rapportés dans la littérature indiquent que l’opérateur de croisement uniforme domine encore ceux à un point et à deux points.
Coloration de graphe
En théorie des graphes, la coloration de graphe consiste à attribuer une couleur à chacun de ses sommets de manière que deux sommets reliés par une arête soient de couleur différente. On cherche souvent à utiliser le nombre minimal de couleurs, appelé nombre chromatique.

Est-ce que ça fonctionne?
Il n’y a aucun doute que les algorithmes génétiques peuvent être utilisés pour traiter des problèmes d’optimisation. Leur performance relative varie cependant selon les contextes. Lorsqu’un problème est bien étudié, il est généralement préférable d’avoir recours à des algorithmes spécialisés qui peuvent tirer avantage de certaines structures spécifiques. Pour le problème TSP par exemple, des approches basées sur la programmation en nombres entiers peuvent maintenant résoudre de façon optimale des exemplaires de plusieurs dizaines de milliers de villes. Il serait donc mal avisé d’utiliser un algorithme génétique pour résoudre ce problème (à moins de vouloir étudier leur comportement, ce qui peut être tout à fait légitime et amusant).
Les algorithmes génétiques ont tout de même l’avantage d’être simples à mettre en place. En fait, une méthode de codage, des opérateurs de croisement et de mutation, ainsi qu’une fonction d’évaluation sont suffisants pour utiliser une approche évolutive. On obtient alors une approche robuste qui peut être très utile si la fonction à optimiser est « floue » (fuzzy) ou si on dispose de peu de temps pour étudier le problème à optimiser.
Les algorithmes génétiques peuvent également être combinés à d’autres ap- proches d’optimisation pour donner lieu à des méthodes hybrides très puissantes, souvent parmi les meilleures disponibles. On peut par exemple utiliser des opérateurs de mutation plus sophistiqués pour optimiser le résultat de chaque croisement. Pour l’algorithme hybride résultant, la composante « génétique » vise alors à enrichir la recherche, en misant sur les éléments qui constituent sa force, i.e. l’utilisation d’une population diversifiée qui permet l’accès aux caractéristiques variées de plusieurs individus, et au processus de sélection (artificielle dans ce cas), afin d’orienter l’exploration vers les meilleures régions de l’espace de solutions. C’est bien là l’une des leçons à tirer de l’observation de la nature.
- Voir « Le théorème des quatre couleurs », Accromath, 14.1, 2019. ↩